
Redshift spectrum lets us to query data in s3 buckets using redshift. This scenario is specially interesting in large datawarehouses with data that we do not need to query often but it may be nevessary from time to time to run some of our queries. In this situation, probably we dont want the data to be loaded into our redshift cluster as this may push us to provision larger redshift clusters that the ones we need for procession our usual queries (take into account that redshift clusters are set with specific cpu, ram and space and they can not be totally tailored to our needs, so only few combinations are available)
There are a few requirements however to be able to use redshift spectrum. First, the data loaded will be like an external table in other systems (RDBMS) or like hive external tables. So this means that we can forget about updating or deleting our data. We will only get read only capability, but usually thats we are looking for (think in historical data from already closed exercices, archived data and so on), where the cost of storing it in s3 even in a cool tier can ve several orders of magnitude cheaper than keeping it inside redshift.
There are other technical limitations tough. For example, the s3 bucket has to be in the same region as our redshift cluster, so plan in advance or move the data to another s3 bucket. There are other requirements like permissions and so on, you can read it here.
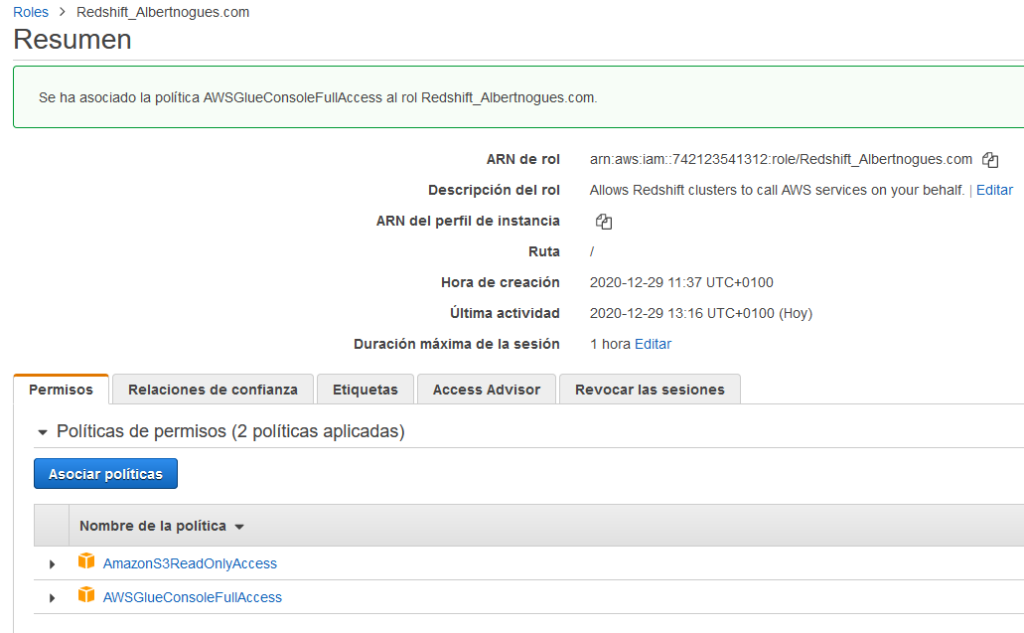
Before starting we need to attach a role to our redshift cluster that grants access to read s3 buckets. If you followed my previous article on redshift you will already have this role, otherwise check how to do it here.
If you followed my previous article, apart of the s3 read only permisison, you need to add the glue catalog permission to create a table. For this, modify the role (or if you’re creating a new one, add the following permission: AWSGlueConsoleFullAccess
For the sake of this exercise I’ve load part of the TPC-DS customer data into a s3 bucket i made public on the Paris region. Then we will create an external customer table pointing to the data in the bucket (which is in fact compressed in gz) and we will query that data from redshift.
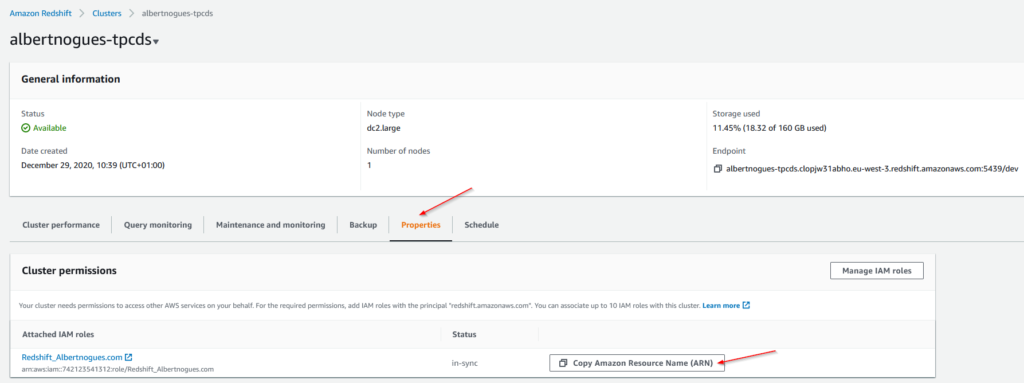
Once the bucket data is loaded, we are ready to go back to our redshift cluster. I’ve used this file for the tests. We will create an external schema and an external customers table. For this we need first to copy the arn of the role we created with the s3 read access. To get that let’s go to our cluster, then click on properties and later on click in Copy Amazon Resource Name (ARN):
Once we have the arn of our role, then run the folloowing in your editor. It will create the external schema in a new spectrum database (feel free to choose any other database name if you need)
create external schema spectrum_albertnogues
from data catalog
database 'spectrum'
iam_role 'arn:aws:iam::742123541312:role/Redshift_Albertnogues.com'
create external database if not exists;Then we are ready to create our external table:
create external table spectrum_albertnogues.customer
(
c_customer_sk int4,
c_customer_id char(16),
c_current_cdemo_sk int4 ,
c_current_hdemo_sk int4 ,
c_current_addr_sk int4 ,
c_first_shipto_date_sk int4 ,
c_first_sales_date_sk int4 ,
c_salutation char(10) ,
c_first_name char(20) ,
c_last_name char(30) ,
c_preferred_cust_flag char(1) ,
c_birth_day int4 ,
c_birth_month int4 ,
c_birth_year int4 ,
c_birth_country varchar(20) ,
c_login char(13) ,
c_email_address char(50) ,
c_last_review_date_sk int4
)
row format delimited
fields terminated by '|'
stored as textfile
location 's3://redshift-spectrum-albertnogues/customers/';As you can see it’s not really 100% the same customers table from the TPC-DS data. This is because external tables do not support primary keys, not null syntax and some other keywords that do not make sense in external tables. Make sure you used the right separator and selected the right format of data (compression is determined by the file extension).
Then, as you will see the table creation takes virtually nothing. This is because in fact, the data is not loaded, its only a shortcut to our s3 data. But to make sure it’s working we can run a few queries to our new table:
select count(*) from spectrum_albertnogues.customer;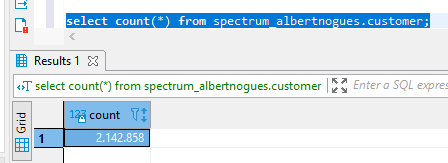
And to make sure data is properly loaded, we can query it as well:
select * from spectrum_albertnogues.customer LIMIT 5;
As a last example, if you run my previous blog post on redshift, we can now join our new external customers table with our web returns fact table, to see how many objects these users returned depending on their origin country, to see if there is any pattern or not.
select c_birth_country as customer_birth_country, sum(wr_return_quantity) as qty_returned_total
from web_returns,
date_dim,
spectrum_albertnogues.customer
where wr_returned_date_sk = d_date_sk
and d_year =2002
and wr_returning_customer_sk = c_customer_sk
group by c_birth_country
order by 2 desc;Of course the query should take a bit more since the data is not inside redshift, and needs to be fetched from s3 but we can get our output quite fast and easily:
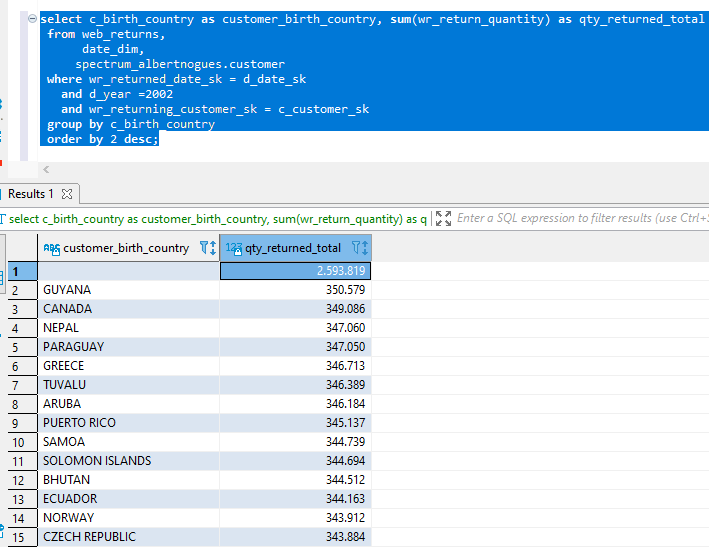
Thats it!. For more advanced topics like performance improvements when querying from s3 and others, you can read here and here. I recommend basically partitioning, a splittable file format like parquet compressed with snappy or some other codec, small files (but not very small), add as many filers as you can to avoid retrieving unnecesary data, and if you use a columnar format like parquet, you will avoid fetching unused columns in your select statement. This is important (and can have a huge impact in costs) because now it’s the time of discussing the price of all this.
Bear in mind that AWS charges 5 dollars for each Terabyte of data scanned from s3 with spectrum, so make sure you do the right usage on this (only data infrequently queried) and do not overestimate these charges as they grew quickly.
For expert advice or project requests you can contact me here. Happy Querying!