
Data Quality Checks with Soda-Core in Databricks
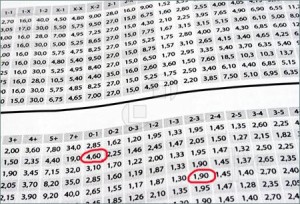
It’s easy to do data quality checks when working with spark with the soda-core library. The library has support for spark dataframes. I’ve tested it within a databricks environment and it worked quite easily for me. For the examples of this article i am loading the customers table from the tpch delta tables in the …