
Most of the developments I see inside databricks rely on fetching or writing data to some sort of Database.
Usually the preferred method for this is though the use of jdbc driver, as most databases offer some sort of jdbc driver.
In some cases, though, its also possible to use some spark optimized driver. This is the case in Azure SQL / SQL Server. We have still the option to use the standard jdbc driver (what most people do because it’s standard to all databases) but we can improve the performance by using a specific spark driver. Till some time ago it was only supported with the Scala API but now it’s possible to be used in Python and R as well, so there is no reason not to give it a try.
In this article we will see the two options to make this connectivity. For the test purposes we will connect to an Azure SQL in the same region (West Europe).
Connecting to AzureSQL through jdbc driver.
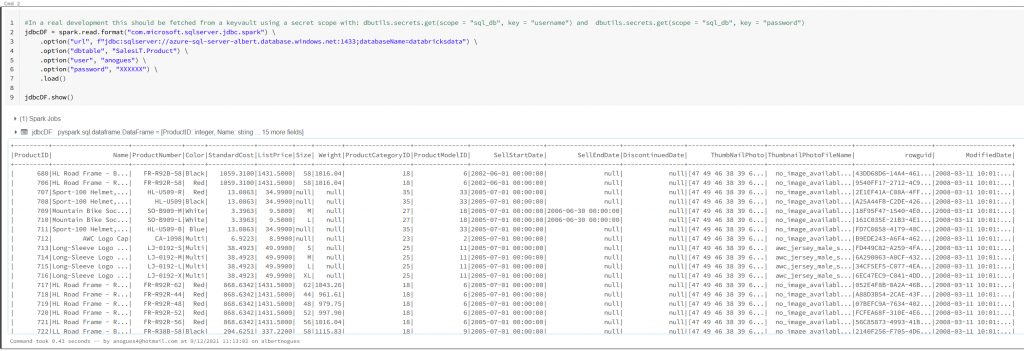
In this case the jdbc driver is already shipped in the databricks cluster, we do not need to install anything. We just can connect directly. Lets see how (We have a scala example here but i will use python for this example)
#In a real development this should be fetched from a keyvault using a secret scope with: dbutils.secrets.get(scope = "sql_db", key = "username") and dbutils.secrets.get(scope = "sql_db", key = "password")
jdbcDF = spark.read.format("jdbc") \
.option("url", f"jdbc:sqlserver://azure-sql-server-albert.database.windows.net:1433;databaseName=databricksdata") \
.option("dbtable", "SalesLT.Product") \
.option("user", "anogues") \
.option("password", "XXXXXX") \
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver") \
.load()
jdbcDF.show()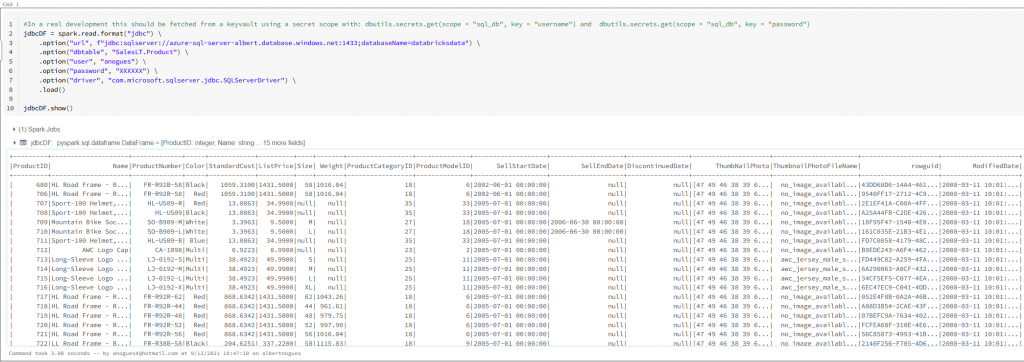
So as we saw we have been able to connect successfully to our Azure SQL DB using the jdbc driver shipped with databricks. Lets now try to change to the spark optimized driver
Connecting to AzureSQL through the spark optimized driver
To connect using the spark optimized driver, first we need to install the driver in the cluster, as it’s not available by default.
The driver is available in Maven for both spark 2.X and 3.X. In the microsoft website we can find more information on where to get them and how to use them. For this exercise purposes we will inbstall it through databricks libraries, using maven. Just add in the coordinates box the following: com.microsoft.azure:spark-mssql-connector_2.12:1.2.0 as can be seen in the image below
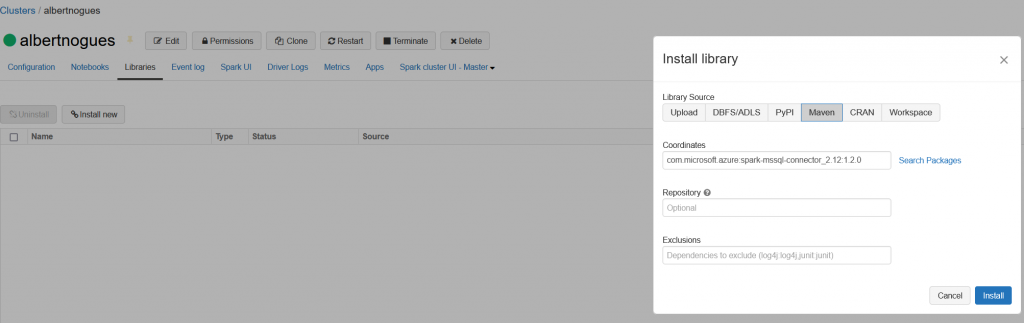
Once installed we should see a green dot next to the driver, and this will mean the driver is ready to be used. We go back to our notebook and try
#In a real development this should be fetched from a keyvault using a secret scope with: dbutils.secrets.get(scope = "sql_db", key = "username") and dbutils.secrets.get(scope = "sql_db", key = "password")
jdbcDF = spark.read.format("com.microsoft.sqlserver.jdbc.spark") \
.option("url", f"jdbc:sqlserver://azure-sql-server-albert.database.windows.net:1433;databaseName=databricksdata") \
.option("dbtable", "SalesLT.Product") \
.option("user", "anogues") \
.option("password", "XXXXXX") \
.load()
jdbcDF.show()If we see an error like java.lang.ClassNotFoundException: com.microsoft.sqlserver.jdbc.spark this means that the driver can’t be found, so probably it’s not properly installed. Check back the libraries in the cluster and make sure the status is installed. If all goes well we should see again our dataframe:
The reason why we should use the optimized spark driver is usually because of performance reasons. Microsoft claims its about 15x faster than the jdbc one. But there is more. The spark driver also allows AAD authentication either by using a service principal or an AAD account, apart of course from the native sql server authentication. Lets try if it works with an AAD account:
jdbcDF = spark.read \
.format("com.microsoft.sqlserver.jdbc.spark") \
.option("url", f"jdbc:sqlserver://azure-sql-server-albert.database.windows.net:1433;databaseName=databricksdata") \
.option("dbtable", "SalesLT.Product") \
.option("authentication", "ActiveDirectoryPassword") \
.option("user", "sqluser@anogues4hotmail.onmicrosoft.com") \
.option("password", "XXXXXX") \
.option("encrypt", "true") \
.option("hostNameInCertificate", "*.database.windows.net") \
.load()
jdbcDF.show()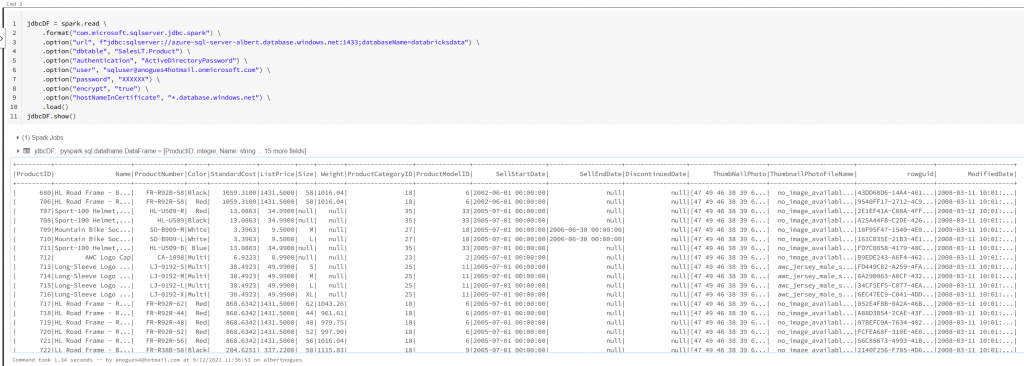
For using a service principal you need to generate a token. In python this can be accomplished with the adal library (That needs to be installed in the cluster as well from pypi). You have a sample notebook in microsoft spark driver github account here.
More information about the driver can be found on the microsoft github repository here.