
Following the previous redshift articles in this one I will explain how to export data from redshift to parquet in s3. This can be interesting when we want to archive (infrequently queried) data to be queried cheaper with spectrum, or to store in s3 archive, or to export to another storage solution like glacier.
The first thing we need to do is to modify our redshift cluster iam role to allow write to s3. We go to our cluster in the redshift panel, we click on properties, and then we will see the link to the iam role attached to the cluster. we click on it and it will open the IAM role page.

Then we add the policy named AmazonS3ReadOnlyAccess as shown in the following pic:
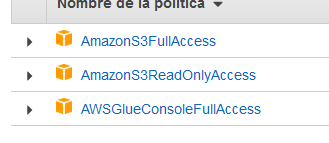
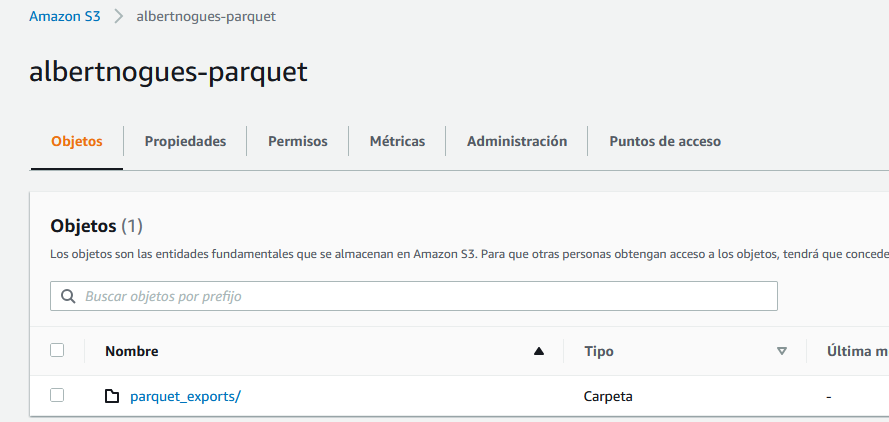
And with this we already have all the required permissions ready. The next step now is to make sure we have an available s3 bucket. I’ve created one for the demo purposes with a folder called parquet_exports.
For starting the extraction, we will use the customers table we used in the previous articles. This table was loaded as well from the TPC-DS test data from s3 in a gzip file but now it sits inside our redshift node. The instruction to unload the data is called UNLOAD 🙂
Since we want our data in parquet + snappy format, which is usually the recommended way (avro is not supported in redshift UNLOAD, only CSV and parquet), we need to express it in the unload statement.
Contrary to spectrum, here we can unload data to buckets in another region. So if thats your need make sure you fill the bucket region as well in the unload statement. The statement is as follows
UNLOAD ('select-statement')
TO 's3://object-path/name-prefix'
authorization
[ option [ ... ] ]
where option is
{ [ FORMAT [ AS ] ] CSV | PARQUET
| PARTITION BY ( column_name [, ... ] ) [ INCLUDE ]
| MANIFEST [ VERBOSE ]
| HEADER
| DELIMITER [ AS ] 'delimiter-char'
| FIXEDWIDTH [ AS ] 'fixedwidth-spec'
| ENCRYPTED [ AUTO ]
| BZIP2
| GZIP
| ZSTD
| ADDQUOTES
| NULL [ AS ] 'null-string'
| ESCAPE
| ALLOWOVERWRITE
| PARALLEL [ { ON | TRUE } | { OFF | FALSE } ]
| MAXFILESIZE [AS] max-size [ MB | GB ]
| REGION [AS] 'aws-region' }As you can see, it allows to pass a select statement instead of a table name. This way we can project the required columns and there is no need to export the whole table if we do not need it. We can also specify the max filesize. Usually with parquet 256 MB is a good split size. And make sure with Parquet not to specify any compression format as otherwise it will crash, as by default redshift already compresses it with Snappy.
To run the export we also need to fetch the arn of our redshift role, and incliude it just after the bucket path:
UNLOAD ('select * from customer')
TO 's3://albertnogues-parquet/parquet_exports/'
iam_role 'arn:aws:iam::742123541312:role/Redshift_Albertnogues.com'
FORMAT AS PARQUET
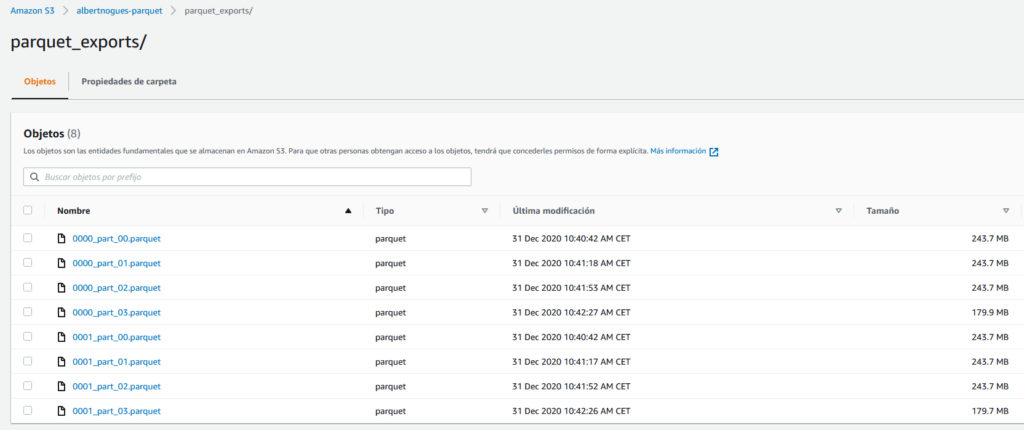
MAXFILESIZE 256 MBAfter about two minutes, the query finished sucessfully. We can go to our s3 bucket to see the parquet files there and check that the split file size is the one we requested
We can check first the size of the table in redshift with the following query:
SELECT "table", tbl_rows, size size_in_MB FROM SVV_TABLE_INFO
order by 1| Table | Num Rows | Size (MB) |
| customer | 30.000.000 | 2098 |
So its quite clear that the export looks ok as the size is similar. We can now download one fo the parquet files and inspect it with some parquet tool analyzer. I tend to use the python version of parquet-tools based on apache arrow project. You can install it with:
pip install parquet-toolsAnd then we will inspect the file with the following:
parquet-tools inspect 0001_part_03.parquet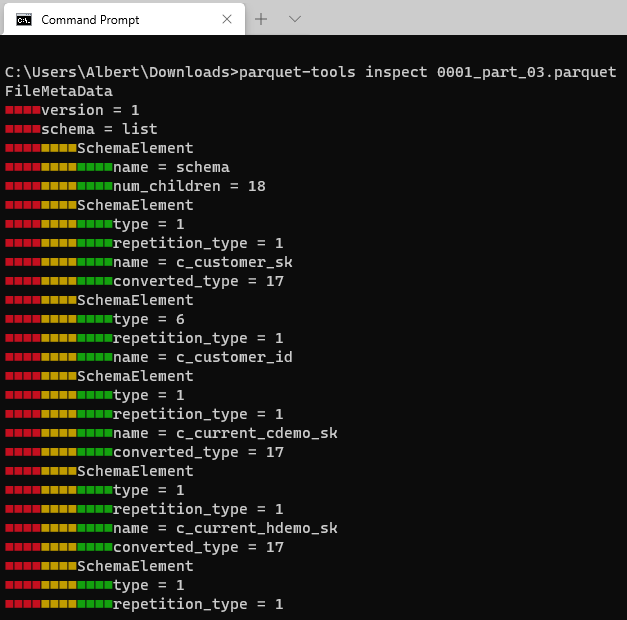
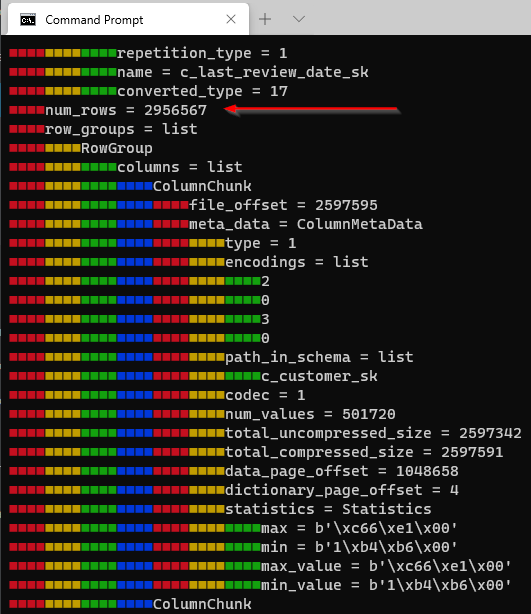
And if we scroll down a little bit we can see the total number of files on our parquet file: