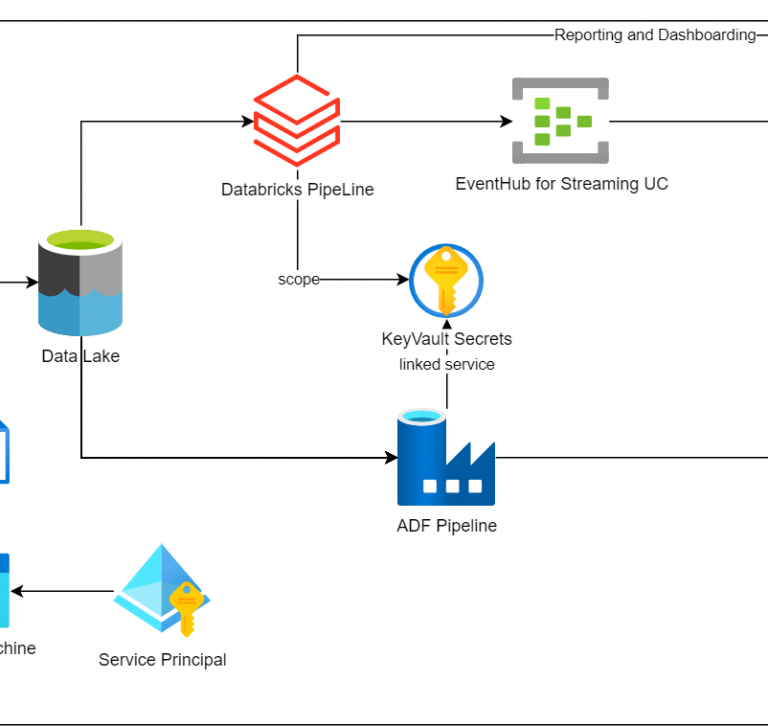

Query Delta Tables in the DataLake from PowerBi with Databricks
There are several ways to query delta tables from PowerBi. We are going to cover the 4th method here. To do it first we need a service princpal, a secret scope pointing to a databricks keyvault and the password of the SPN stored in this keyvault. Once we have this, the first step is to …