
There are several ways to query delta tables from PowerBi.
- You can use snowflake with external stages reading delta data from the DL,
- The parquet connector and directly query the data from the datalake (caution as this method does not support SPNs and also you can only use delta tables with only 1 version)
- or with Delta Sharing plugin (Not possible currently in danone due not having unity catalog)
- Or the recommended way, using databricks to do it (With a SPN + Databricks CLuster (either DataEngineering or SQL Warehouse))
We are going to cover the 4th method here. To do it first we need a service princpal, a secret scope pointing to a databricks keyvault and the password of the SPN stored in this keyvault.
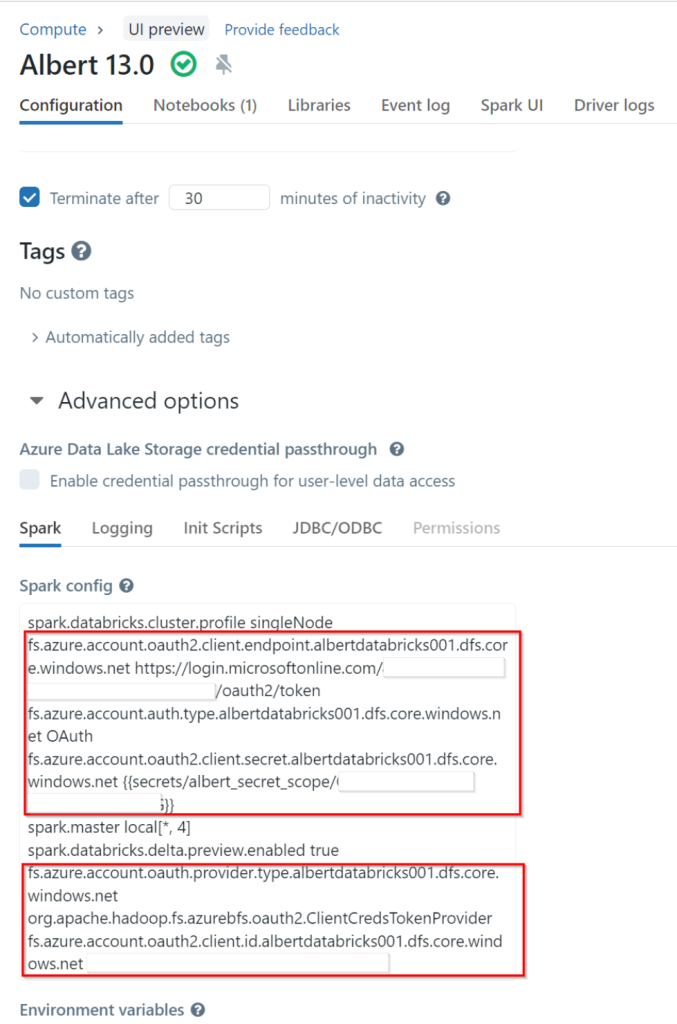
Once we have this, the first step is to set up the cluster with the credentials to access the datalake. For this we need to configure the spark variables of our databricks cluster. You can follow the guide here.
After that you cluster should have the credentials in the spark conf section, something like this:
The second step is creating an EXTERNAL table in Databricks to pint to our delta table(s). For this we connect to our databricks workspace with the previous configuration, and create a new notebook and define the external tables we want, something like this:
%sql
CREATE TABLE IF NOT EXISTS anogues.customers_external
LOCATION 'abfss://raw@albertdatabricks001.dfs.core.windows.net/customers'Make sure the location is the right one otherwise when we query the data we will get either an error or no results.
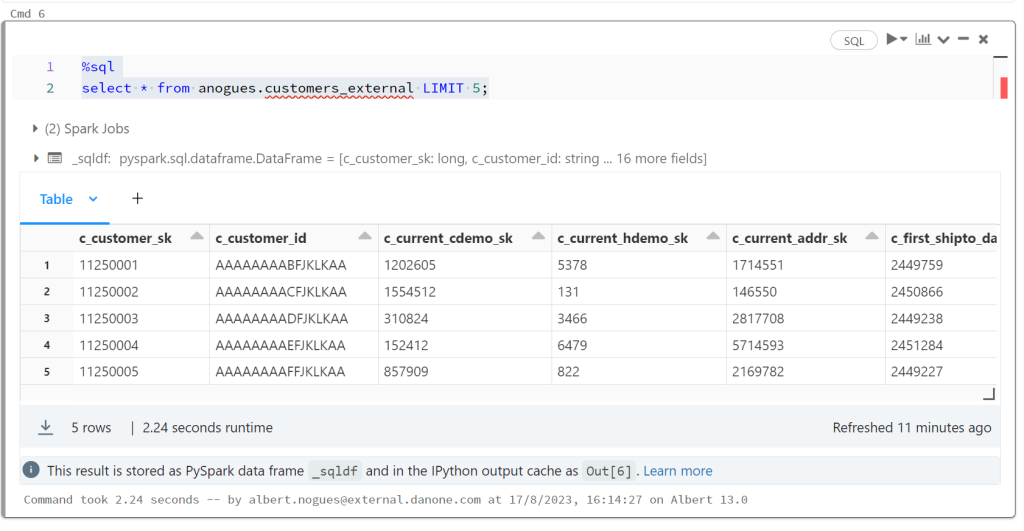
Once we have this we can query our external table and verify we can see the data:
%sql
select * from anogues.customers_external LIMIT 5;And providing we did it right we should see the data. There is no need to define the table columns as delta uses parquet under the hood so it’s a self contained format where the schema is stored alongside with the data.
Once we confirmed this is working we can go to powerbi, try to import data using the Databricks Connector:
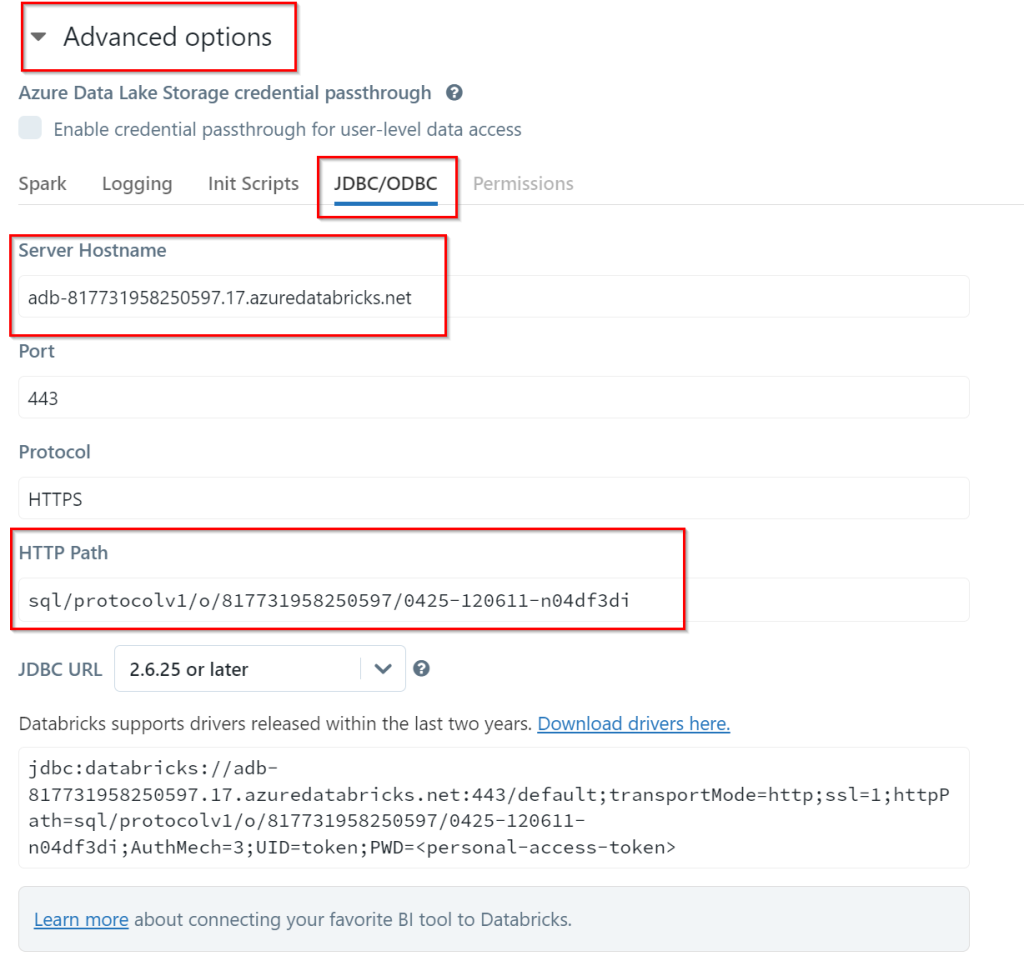
To configure the connector we need to get some details from our cluster. These can be found in the advanced options of our cluster, in the tab JDBC/ODBC
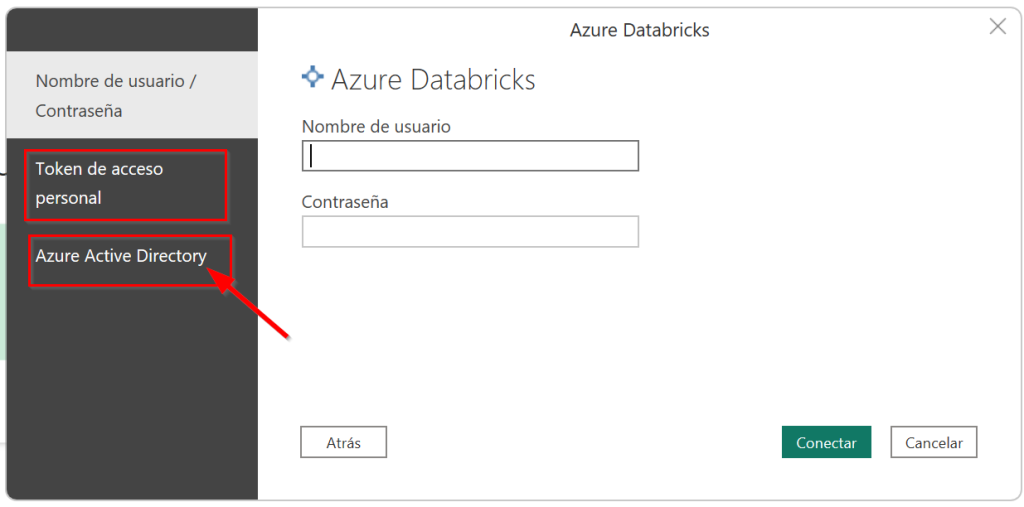
On the following screen we need to select our authentication options to connect to the databricks cluster. Since we have SAML + SCIM enabled in our workspaces the user and password option is not possible. Either we need a databricks PAT token or use Azure AD. I recommend the latter:
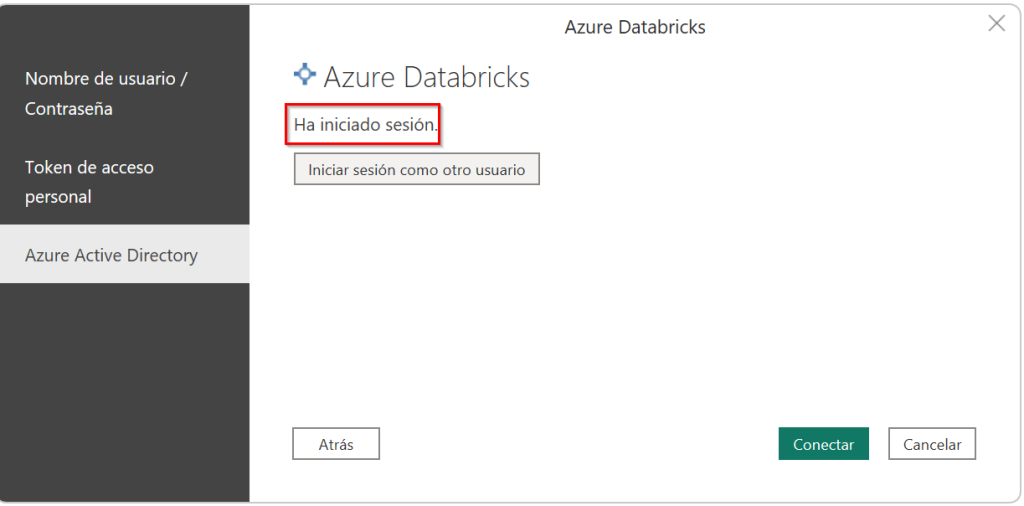
We click on it and select our AAD account. If all works well our session will be started. We should see it in the screen:
Then we click on connect, and we can see our data. Since we don’t have unity catalog, our table should appear in the hive_metastore catalog. There we can find our database and inside our table(s). We click and either load all the tables we want or start transforming them inside powerbi, like we will do with any other data source.
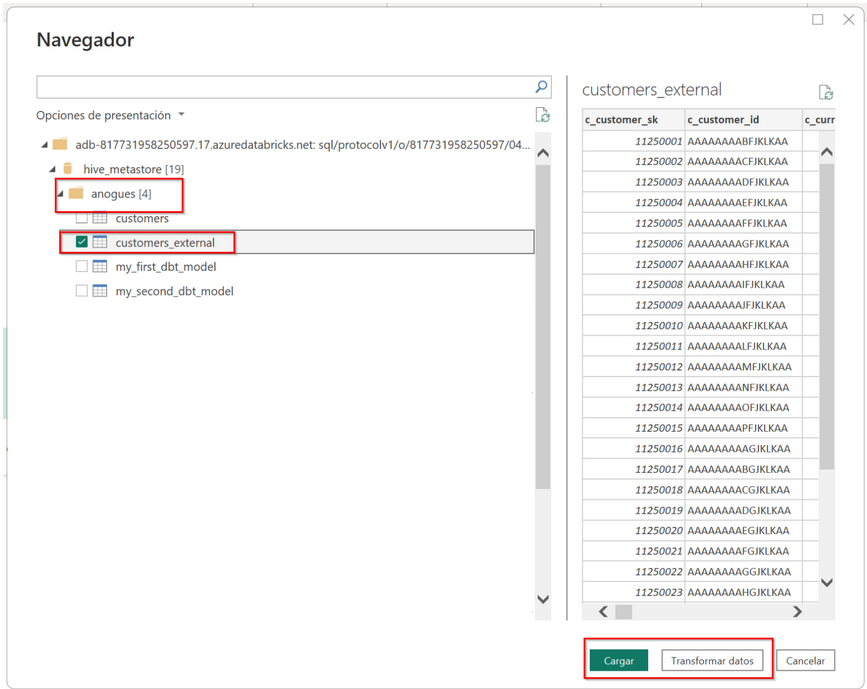
For more help here is the detail of the powerbi databricks connector: Connect Power BI to Azure Databricks – Azure Databricks | Microsoft Learn