
It’s easy to do data quality checks when working with spark with the soda-core library. The library has support for spark dataframes. I’ve tested it within a databricks environment and it worked quite easily for me.
For the examples of this article i am loading the customers table from the tpch delta tables in the databricks-datasets folder.
First of all we need to install the library either scoped to our Databricks notebook or on our cluster. In my case i will install it notebook scoped:
%pip install soda-core-spark-dfThen we create a dataframe from the tpch customers table:
#We create a table and read it into a dataframe
customer_df = spark.read.table("delta.`/databricks-datasets/tpch/delta-001/customer/`")We create a temporary view for our dataframe so soda can query the data and run the checks:
#We create a TempView
customer_df.createOrReplaceTempView("customer")And here it comes the whole soda core. We will define the checks using yaml syntax:
from soda.scan import Scan
scan = Scan()
scan.set_scan_definition_name("Databricks Test Notebook")
scan.set_data_source_name("customer")
scan.add_spark_session(spark, data_source_name="customer")
#YAML Format
checks = '''
checks for customer:
- row_count > 0
- invalid_percent(c_phone) = 0:
valid regex: ^[0-9]{2}[-][0-9]{3}[-][0-9]{3}[-][0-9]{4}$
- duplicate_count(c_phone) = 0:
name: No duplicate phone numbers
- invalid_count(c_mktsegment) = 0:
invalid values: [HOUSEHOLD]
name: HOUSEHOLD is not allowed as a Market Segment
'''
# you can use add_sodacl_yaml_file(s). Useful if the tests are in a github repo or FS
scan.add_sodacl_yaml_str(checks)
scan.execute()
print(scan.get_logs_text())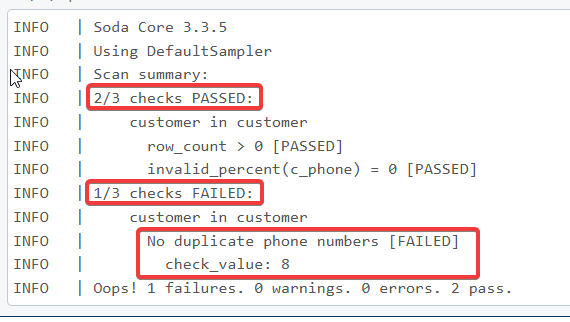
More info: Add Soda to a Databricks notebook | Soda Documentation
List of validations: Validity metrics | Soda Documentation and SodaCL metrics and checks | Soda Documentation
We can somewhat enhance it and generate a Spark Dataframe all out of the list of our warnings or error validation checks:
from datetime import datetime
schema_checks = 'datasource STRING, table STRING, rule_name STRING, rule STRING, column STRING, check_status STRING, number_of_errors_in_sample INT, check_time TIMESTAMP'
list_of_checks = []
for c in scan.get_scan_results()['checks']:
list_of_checks = list_of_checks + [[scan.get_scan_results()['defaultDataSource'], c['table'], c['name'], c['definition'], c['column'], c['outcome'], 0 if 'pass'in c['outcome'] else int(c['diagnostics']['blocks'][0]['totalFailingRows']), datetime.strptime(scan.get_scan_results()['dataTimestamp'], '%Y-%m-%dT%H:%M:%S%z')]]
list_of_checks_df = spark.createDataFrame(list_of_checks,schema_checks)
display(list_of_checks_df)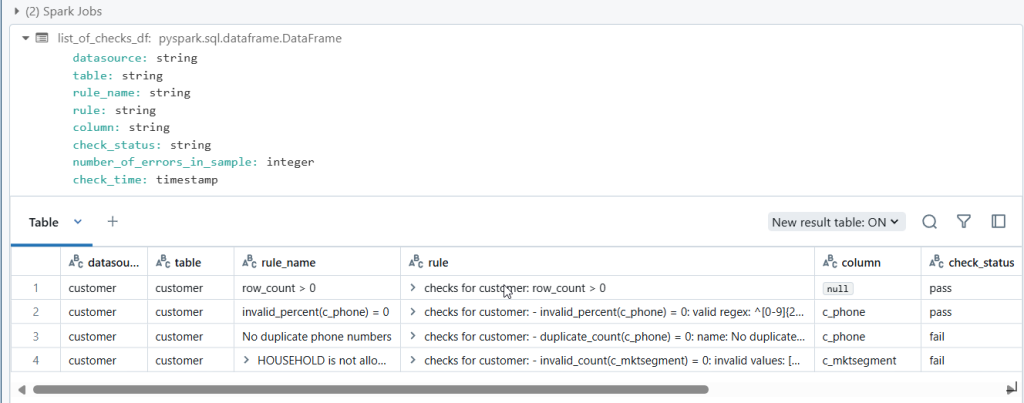
In the case we have the yaml file in our github repo, we can read it and pass it. Or If we are working with Databricks repos and the file is part of out repo we can load it locally
Accessing a remote file and reading it with requests:
#Trying to use a remote yaml file to enforce rules. We can upload it to a github of our own and use it in opur notebook.
#I've created a public repo so i dont need to authenticate to github, but in a real world scenario we should use private repo + secret scopes
customer_quality_rules = 'https://raw.githubusercontent.com/anogues/soda-core-quality-rules/main/soda-core-quality-rules-customer.yaml'
import requests
scan.add_sodacl_yaml_str(requests.get(customer_quality_rules).text)Or we can load it locally if we are using databricks repos:
scan.add_sodacl_yaml_file("your_file.yaml")