
In this article we will see how to provision an azure synapse cluster, load some large quantity of data from azure blob storage and run a query to see the contents and check performance. I plan to write a serie of articles arround data warehousing in the cloud so check out for new articles soon.
I’ve split the article in 3 steps that cover diverse topics:
- Part 1. Deploying a synapse cluster.
- Part 2. Load TPC-DS data.
- Part 3. Run queries to verify the performance.
- We need to create a synapse cluster. We head to the azure portal and we will create a Gen2: DW100c cluster, which is the cheapest option on sale for a bit more than 1.50 USD per hour. For this exercise I didnt create a synapse workspace, i just went with the “Dedicated SQL pool” because i am only interested in the synapse db warehouse, not spark or other engines this time. Check the following documentation for more help.
After a few minutes we will have the synapse warehouse ready.
Once created, we can take the url and connect from Dbeaver (or any other editor, you can use the free Azure Data Studio too!) to see if all is ok:
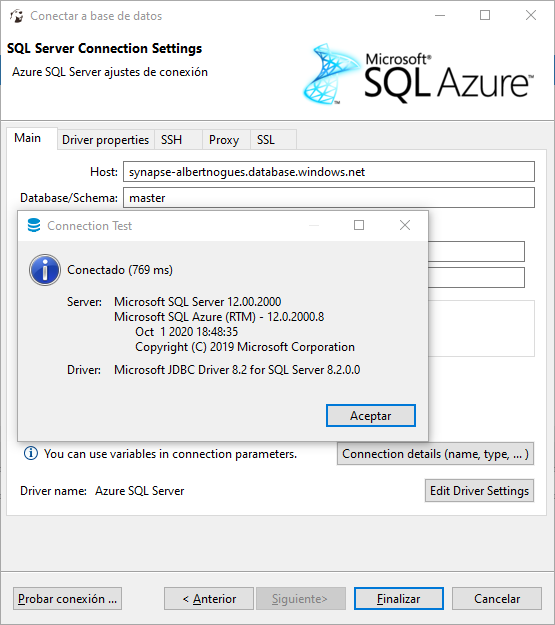
If you have trouble, make sure you have your ip added in the whitelist of the firewall section of your synapse instance and that is open to the public:
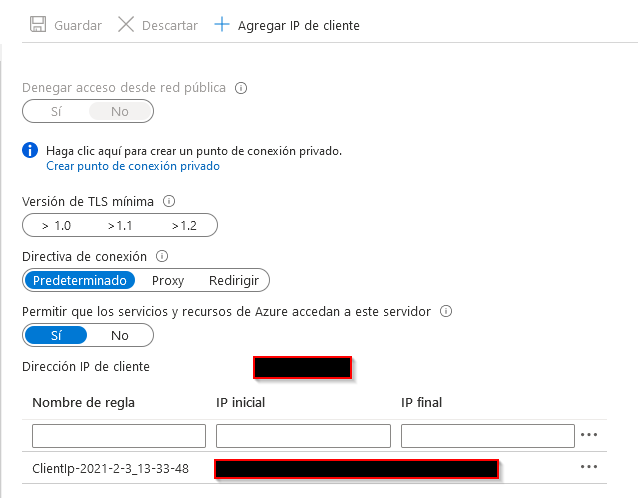
2. Load TPC-DS Data
Unfortunatelly I haven’t been able to found any TPC-DS data in azure blob storage. The table structure I am going to use, is the fivetran table structure for azure synapse found in their repo here, albeit i will do a modification stated in this atscale pdf as I think it makes more sense. Basically, for the dimension tables we will replicate them and create a clustered columnstore index, and for the fact table, we will use a hash distribution by the sr_item_sk column. They also suggest a columnstore index order in the fact tables but for our test i dont think it’s necessary.
The table structure, extracted from fivetran repo that we are going to replicate is the same set of 4 tables i did for my previous article for redshift, that you can find here. Here is the modified list:
create table customer_address (
ca_address_sk bigint,
ca_address_id nvarchar(16),
ca_street_number nvarchar(10),
ca_street_name nvarchar(60),
ca_street_type nvarchar(15),
ca_suite_number nvarchar(10),
ca_city nvarchar(60),
ca_county nvarchar(30),
ca_state nvarchar(2),
ca_zip nvarchar(10),
ca_country nvarchar(20),
ca_gmt_offset float,
ca_location_type nvarchar(20)
)
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED COLUMNSTORE INDEX
)
GO
create table customer (
c_customer_sk bigint,
c_customer_id nvarchar(16),
c_current_cdemo_sk bigint,
c_current_hdemo_sk bigint,
c_current_addr_sk bigint,
c_first_shipto_date_sk bigint,
c_first_sales_date_sk bigint,
c_salutation nvarchar(10),
c_first_name nvarchar(20),
c_last_name nvarchar(30),
c_preferred_cust_flag nvarchar(1),
c_birth_day int,
c_birth_month int,
c_birth_year int,
c_birth_country nvarchar(20),
c_login nvarchar(13),
c_email_address nvarchar(50),
c_last_review_date nvarchar(10)
)
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED COLUMNSTORE INDEX
)
GO
create table date_dim (
d_date_sk bigint,
d_date_id nvarchar(16),
d_date nvarchar(10),
d_month_seq int,
d_week_seq int,
d_quarter_seq int,
d_year int,
d_dow int,
d_moy int,
d_dom int,
d_qoy int,
d_fy_year int,
d_fy_quarter_seq int,
d_fy_week_seq int,
d_day_name nvarchar(9),
d_quarter_name nvarchar(6),
d_holiday nvarchar(1),
d_weekend nvarchar(1),
d_following_holiday nvarchar(1),
d_first_dom int,
d_last_dom int,
d_same_day_ly int,
d_same_day_lq int,
d_current_day nvarchar(1),
d_current_week nvarchar(1),
d_current_month nvarchar(1),
d_current_quarter nvarchar(1),
d_current_year nvarchar(1)
)
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED COLUMNSTORE INDEX
)
GO
create table web_returns (
wr_returned_date_sk bigint,
wr_returned_time_sk bigint,
wr_item_sk bigint,
wr_refunded_customer_sk bigint,
wr_refunded_cdemo_sk bigint,
wr_refunded_hdemo_sk bigint,
wr_refunded_addr_sk bigint,
wr_returning_customer_sk bigint,
wr_returning_cdemo_sk bigint,
wr_returning_hdemo_sk bigint,
wr_returning_addr_sk bigint,
wr_web_page_sk bigint,
wr_reason_sk bigint,
wr_order_number bigint,
wr_return_quantity int,
wr_return_amt float,
wr_return_tax float,
wr_return_amt_inc_tax float,
wr_fee float,
wr_return_ship_cost float,
wr_refunded_cash float,
wr_reversed_charge float,
wr_account_credit float,
wr_net_loss float
)
WITH
(
DISTRIBUTION = HASH(wr_item_sk),
CLUSTERED COLUMNSTORE INDEX
)
GO19:33:36Started executing query at Line 2
Commands completed successfully.
19:33:36Started executing query at Line 23
Commands completed successfully.
19:33:36Started executing query at Line 50
Commands completed successfully.
19:33:36Started executing query at Line 87
Commands completed successfully.
Total execution time: 00:00:25.515So we are good for the table structure. Its now time to import the data. We can try to copy it from an azure blob storage where fivetran has left the data already generated. I tried with their suggested COPY INTO COMMAND but didnt work for me because the row terminator was not specified, so if you have problems use the following statements that worked for me:
copy into date_dim
from 'https://fivetranbenchmark.blob.core.windows.net/tpcds/tpcds_1000_dat/date_dim/'
with (file_type = 'CSV', fieldterminator = '|', ENCODING = 'UTF8', ROWTERMINATOR='0X0A');
copy into customer
from 'https://fivetranbenchmark.blob.core.windows.net/tpcds/tpcds_1000_dat/customer/'
with (file_type = 'CSV', fieldterminator = '|', ENCODING = 'UTF8', ROWTERMINATOR='0X0A');
copy into customer_address
from 'https://fivetranbenchmark.blob.core.windows.net/tpcds/tpcds_1000_dat/customer_address/'
with (file_type = 'CSV', fieldterminator = '|', ENCODING = 'UTF8', ROWTERMINATOR='0X0A');
copy into web_returns
from 'https://fivetranbenchmark.blob.core.windows.net/tpcds/tpcds_1000_dat/web_returns/'
with (file_type = 'CSV', fieldterminator = '|', ENCODING = 'UTF8', ROWTERMINATOR='0X0A');And after a few minutes (the fact table is a bit more than 10GB big) you will have your data loaded:
20:07:41Started executing query at Line 125
(73049 rows affected)
(12000000 rows affected)
(6000000 rows affected)
(71997522 rows affected)
Total execution time: 00:06:53.032Note that we are using the 1TB set for Azure Synapse vs the 3 TB test we used for redshift so the comparison wouln’t be fair with this dataset. You can see the difference as our fact table has approximately 1/3 of the rows than in the redshift test. But still with that, we have a table with almost 72 million rows. If you want to generate another bigger set of data you can do it by using the generate_data.sh provided by fivetran and load the data to your own azure blob storage container.
3. Start running the queries.
As I did for the previous test with redshift, I will use query30 to test this. The query can be found in fivetran github repo updated to run with synapse, but you can adapt the original query as you want.
WITH customer_total_return
AS (SELECT wr_returning_customer_sk AS ctr_customer_sk,
ca_state AS ctr_state,
Sum(wr_return_amt) AS ctr_total_return
FROM web_returns,
date_dim,
customer_address
WHERE wr_returned_date_sk = d_date_sk
AND d_year = 2000
AND wr_returning_addr_sk = ca_address_sk
GROUP BY wr_returning_customer_sk,
ca_state)
SELECT TOP 100 c_customer_id,
c_salutation,
c_first_name,
c_last_name,
c_preferred_cust_flag,
c_birth_day,
c_birth_month,
c_birth_year,
c_birth_country,
c_login,
c_email_address,
c_last_review_date,
ctr_total_return
FROM customer_total_return ctr1,
customer_address,
customer
WHERE ctr1.ctr_total_return > (SELECT Avg(ctr_total_return) * 1.2
FROM customer_total_return ctr2
WHERE ctr1.ctr_state = ctr2.ctr_state)
AND ca_address_sk = c_current_addr_sk
AND ca_state = 'IN'
AND ctr1.ctr_customer_sk = c_customer_sk
ORDER BY c_customer_id,
c_salutation,
c_first_name,
c_last_name,
c_preferred_cust_flag,
c_birth_day,
c_birth_month,
c_birth_year,
c_birth_country,
c_login,
c_email_address,
c_last_review_date,
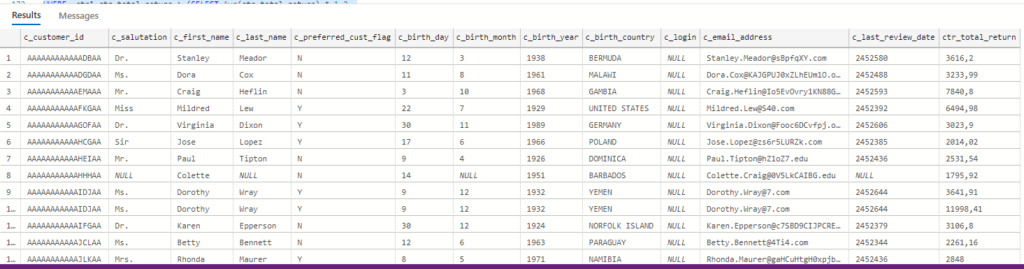
ctr_total_returnAnd the result:
20:31:22Started executing query at Line 145
(100 rows affected)
Total execution time: 00:01:40.416And a pic with the 100 first rows: